Jim's Blog
Toggle navigation
Jim's Blog
Home
About Me
Archives
Tags
群晖存储池损毁解决方法探索
2026-02-26 09:56:31
505
0
0
jim
先上图: 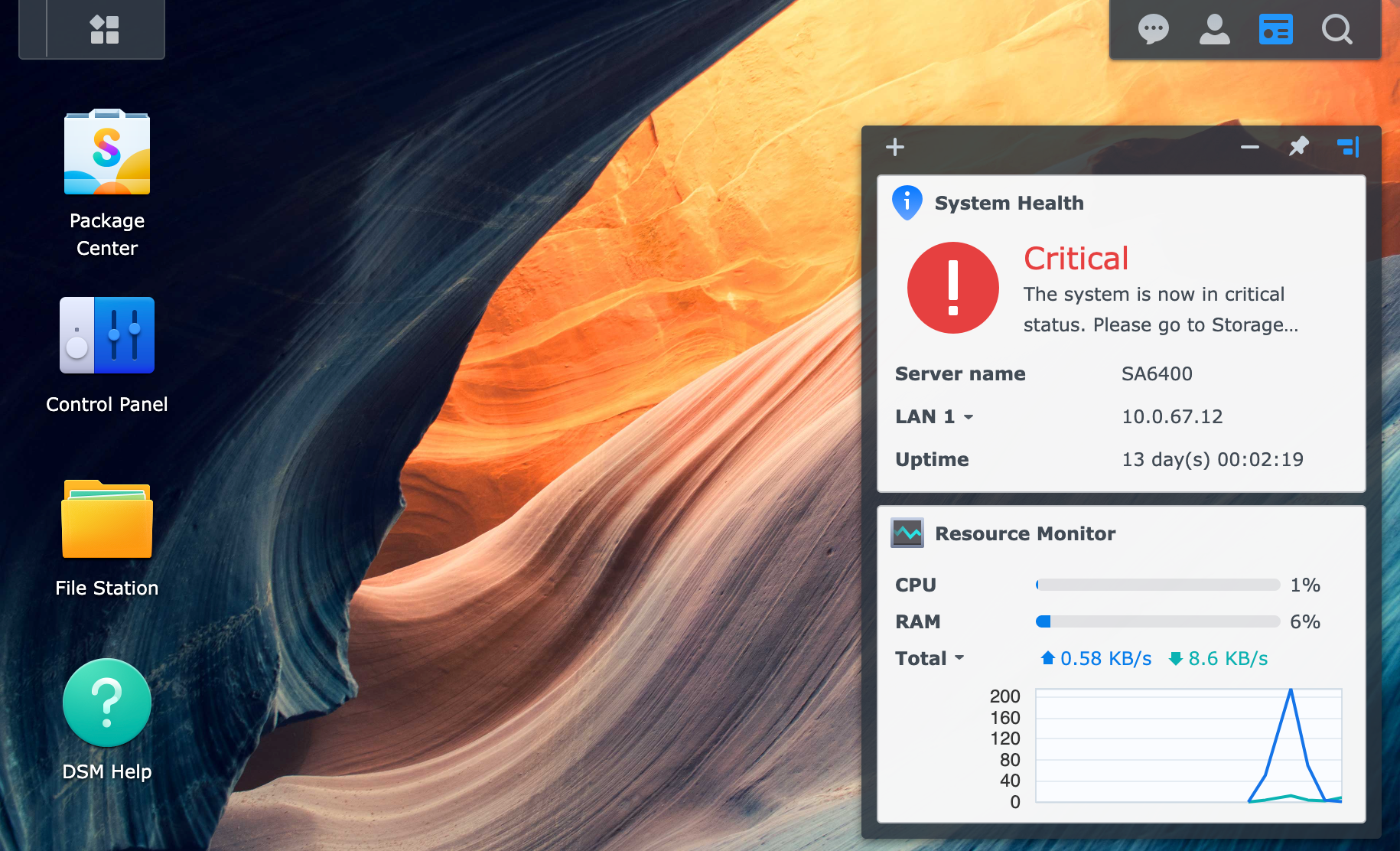 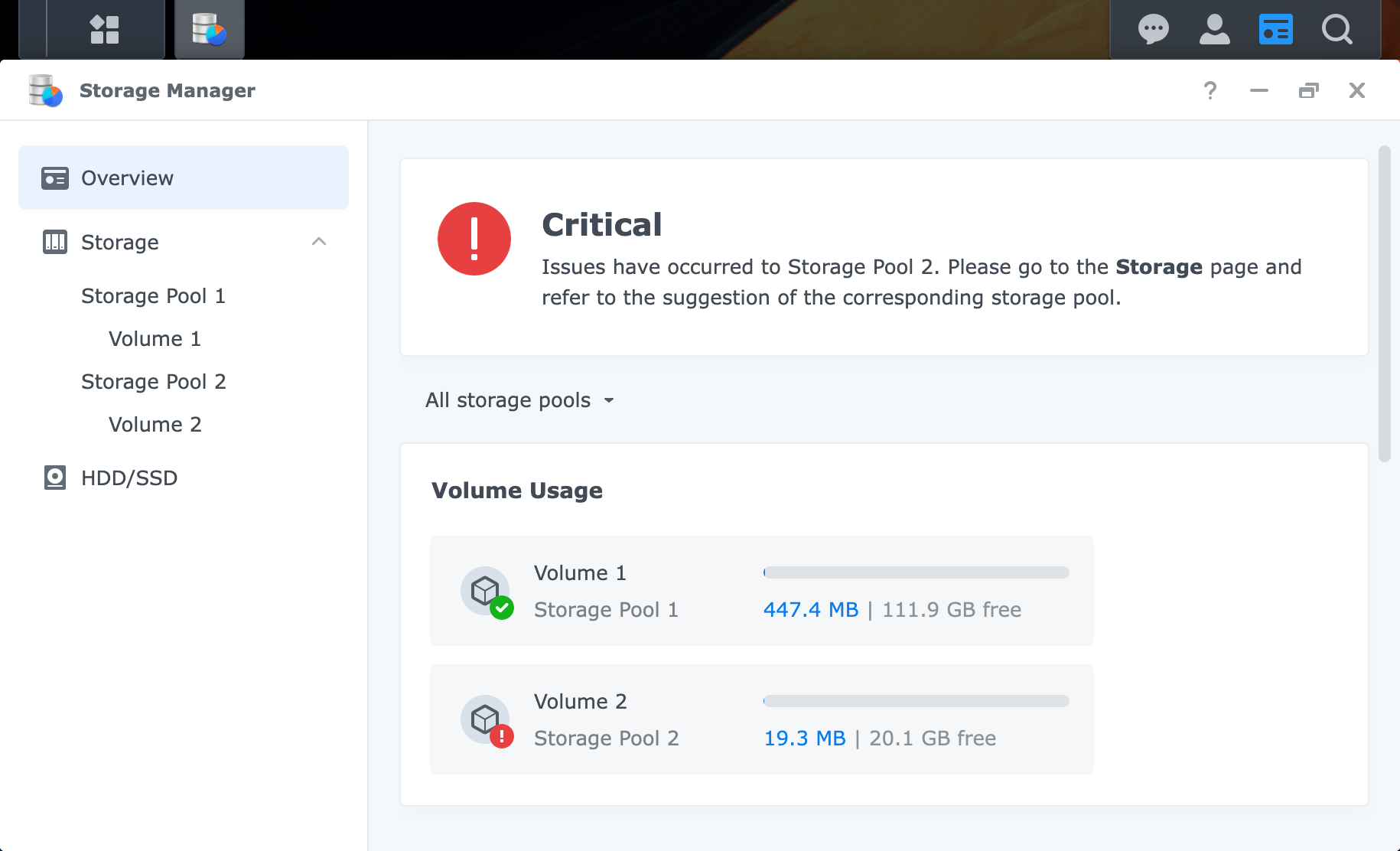 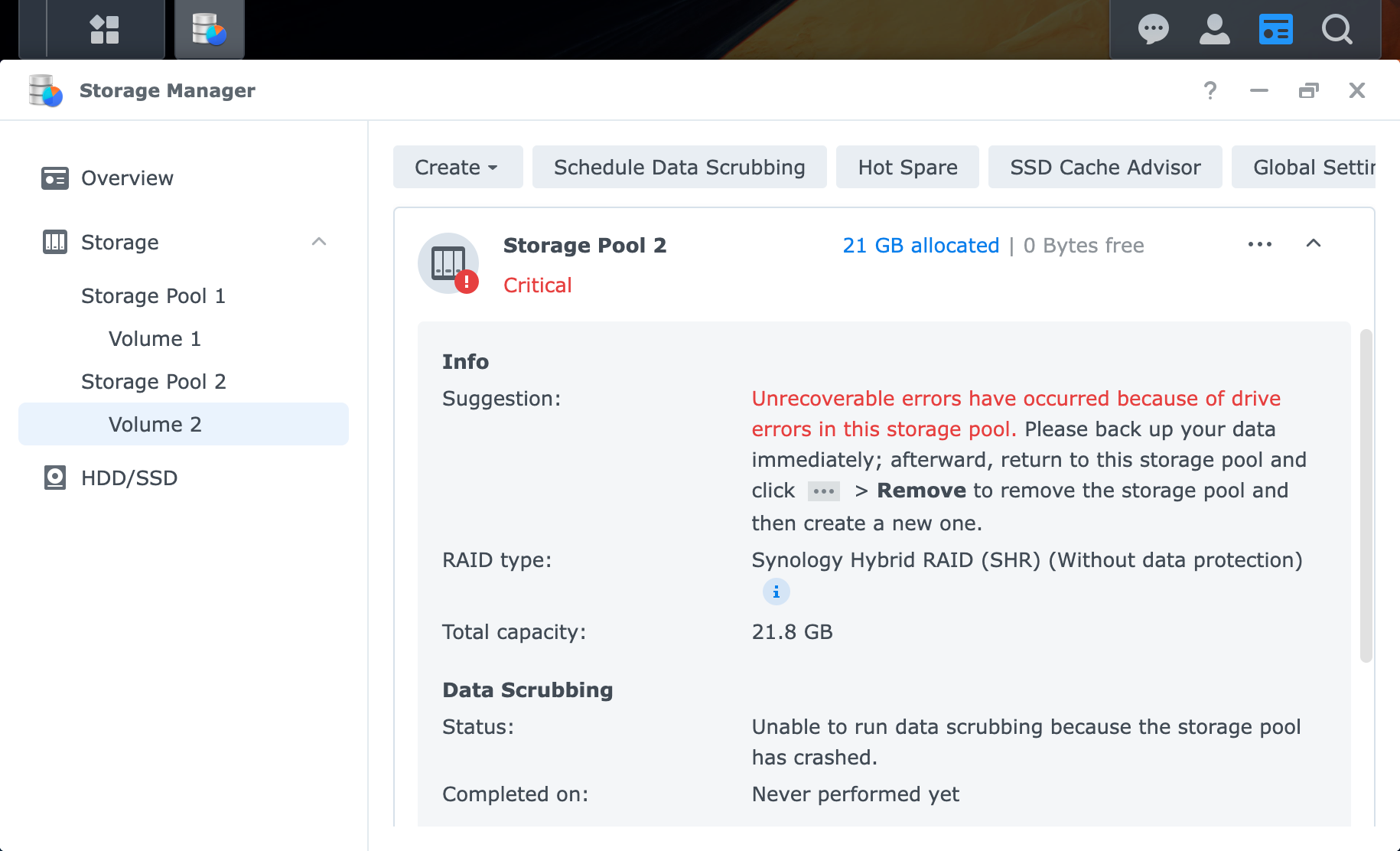 黑群晖玩多了,不少朋友都遇见了上述存储池损毁的情况,一般情况下,只能去手动迁移数据到新的存储池来解决报错,管理页面上甚至都不给迁移,还必须命令行去迁移数据,本文就尝试来解决此类问题 ## 存储池损毁原因分析 可以确定的直接原因是:在存储池读写过程中,默写磁盘出现了读写错误,此时群晖就会标记对应磁盘异常,如果存储池所有磁盘都异常了,则就出现了存储池损毁了 常见的原因使用 AI 总结了一下,供参考 ### 硬件层面原因 * 硬盘物理故障 硬盘损坏:磁头故障、大量坏道、固件损坏等物理问题导致硬盘无法读写 硬盘健康状态异常:SMART 警告或严重错误状态的硬盘未及时更换 硬盘兼容性问题:使用非官方兼容列表中的硬盘,或混用不同类型硬盘(如 SATA 与 SAS、SSD 与 HDD、4K 原生与非 4K 原生硬盘混用) * 非官方硬件兼容性风险 控制器/主板问题:黑群晖使用的非官方主板、SATA 控制器可能存在兼容性问题,导致硬盘识别异常或数据传输错误 电源供应不稳定:劣质电源或供电不足可能导致硬盘突然掉线,尤其在多盘位高负载时 热插拔支持不完善:部分黑群晖硬件不支持真正的热插拔,带电拔插硬盘易造成文件系统损坏 ### 操作与配置原因 * 多块硬盘同时故障/移除 RAID 5:仅支持单块硬盘容错,若同时移除或故障两块硬盘,存储池必然损毁 RAID 6:支持双盘容错,但第三块硬盘故障会导致损毁 修复期间二次故障:在存储池已降级(Degraded)状态下,若再次发生硬盘移除或故障,将直接导致损毁 * 意外操作失误 误拔运行中的硬盘:在扩容或维护时拔错硬盘,且未及时插回原硬盘 强制关机或断电:修复或重建过程中断电,可能损坏存储池元数据,使状态从"降级"变为"崩溃/损毁" 未按流程更换硬盘:未执行"安全移除"直接拔插,或更换时插入错误硬盘 * 存储池类型选择不当 使用无冗余的 RAID 0 或 Basic 单盘:任何单盘故障都直接导致数据丢失,无法修复 ### 软件与系统原因 * DSM 版本与驱动问题 黑群晖引导兼容性问题:引导文件与 DSM 版本不匹配,或硬件驱动异常,可能导致存储池识别错误 系统更新异常:DSM 更新过程中断或失败,可能影响存储池元数据 * 存储池元数据损坏 文件系统错误:Btrfs 或 ext4 文件系统损坏,超级块(Superblock)信息丢失 RAID 阵列信息丢失:阵列配置信息损坏,导致系统无法正确识别硬盘所属关系 ## 解决方法 在出现上述情况,同时反复确认当前硬盘没有问题的时候,可以通过修改磁盘状态来恢复存储池可用状态 以我本地为例,执行下面的命令: ```shell # 去除 error 状态 echo -error > /sys/block/md3/md/dev-sata3p5/state # 重新卷挂在为读写 mount -o remount,rw /volume2 ``` * md3: 根据存储池自行选择 * dev-sata3p5:存储池里对应磁盘分区 * volume2:对应存储池 ### 原理分析 群晖使用 Linux 里的 Multiple Devices 来组装存储池,不过魔改了对应的驱动,在出现问题的分区上,可以看出 `error` 状态: ``` # cat /sys/block/md3/md/dev-sata3p5/state error,in_sync ``` 在上游代码中 https://elixir.bootlin.com/linux/v5.10.55/source/drivers/md/md.c#L2969 的 `state_show` 里是没有 error 输出的,而群晖的内核驱动 https://gitea.home.jim.plus:33333/xpenology/linux-5.10.55-synology-epyc-7.1/src/commit/869b69098c8257d6b99a73ac5b1ce78303f5aa9d/drivers/md/md.c#L3325 则有相关展示: ``` static ssize_t state_show(struct md_rdev *rdev, char *page) { char *sep = ","; size_t len = 0; unsigned long flags = READ_ONCE(rdev->flags); if (test_bit(Faulty, &flags) || (!test_bit(ExternalBbl, &flags) && rdev->badblocks.unacked_exist)) len += sprintf(page+len, "faulty%s", sep); #ifdef MY_ABC_HERE if (test_bit(SynoDiskError, &flags)) len += sprintf(page+len, "error%s", sep); #endif /* MY_ABC_HERE */ if (test_bit(In_sync, &flags)) len += sprintf(page+len, "in_sync%s", sep); if (test_bit(Journal, &flags)) len += sprintf(page+len, "journal%s", sep); ... return len+sprintf(page+len, "\n"); } ``` 所以如果我们可以将 `error` 状态去掉的话,就可以解决了,所幸群晖在 `state_store` 里实现了对应的 `-error` 接口来去除 https://gitea.home.jim.plus:33333/xpenology/linux-5.10.55-synology-epyc-7.1/src/commit/869b69098c8257d6b99a73ac5b1ce78303f5aa9d/drivers/md/md.c#L3384: ``` static ssize_t state_store(struct md_rdev *rdev, const char *buf, size_t len) { /* can write * faulty - simulates an error * remove - disconnects the device * writemostly - sets write_mostly * -writemostly - clears write_mostly * blocked - sets the Blocked flags * -blocked - clears the Blocked and possibly simulates an error * insync - sets Insync providing device isn't active * -insync - clear Insync for a device with a slot assigned, * so that it gets rebuilt based on bitmap * write_error - sets WriteErrorSeen * -write_error - clears WriteErrorSeen * {,-}failfast - set/clear FailFast */ int err = -EINVAL; if (cmd_match(buf, "faulty") && rdev->mddev->pers) { md_error(rdev->mddev, rdev); if (test_bit(Faulty, &rdev->flags)) err = 0; else err = -EBUSY; #ifdef MY_ABC_HERE } else if (cmd_match(buf, "-error")) { clear_bit(SynoDiskError, &rdev->flags); err = 0; #endif /* MY_ABC_HERE */ ... } ``` ## 小结 虽然只有短短的几行命令,实际上由于对 `Multiple Devices` 并不熟悉,花了不少时间去查看 mdadm 输出和 mdstat 状态,最终才发现群晖修改了相关驱动,并留了口子修改状态,不然可能得魔改 mdadm 来修改超级块了 特别注意:本文提供的方法仅适用于当前硬盘等相关硬件无异常的情况,如果根因依旧存在,群晖依旧会标记磁盘为 `error` 的
Pre: No Post
Next:
黑群晖 SA6400 VideoStation 硬解测试
0
likes
505
新浪微博
微信
腾讯微博
QQ空间
人人网
Please enable JavaScript to view the
comments powered by Disqus.
comments powered by
Disqus
Table of content
